

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 자바object다형성
- Spring
- object 배열
- maven repository jar
- nice_v1.1.jar
- 배포시 systempath
- maven jar 배포
- javascript
- maven systempath
- java object 클래스
- java object 다형성
- 스프링
- maver 외부 jar 배포
- 자바스크립트
- 외부 라이브러리 jar 배포
- JS
- object다형성
- map multivaluemap
- niceid_v1.1.jar maven
- 맥북 port kill
- 도커 컨테이너에 mysql
- map vs multivaluemap
- maven 외부 라이브러리 배포
- 졸프
- object tostring
- object 다형성
- 자바
- Object
- java
- object배열
- Today
- Total
모래블로그
정규표현식(Regular Expression) 본문
정규표현식(Regular Expression)
문자열을 처리하는 방법 중 하나로, 특정한 조건의 문자를 검색하거나 치환하는 과정을 매우 간편하게 처리할 수 있도록 하는 수단이다.
반복문이나 조건문을 사용해야할 것 같은 복잡한 코드도 정규표현식을 이용하면 매우 간단하게 표현할 수 있고, 주로 다음과 같은 상황에서 굉장히 유용하게 사용된다.
1. 각각 다른 포맷으로 저장된 엄청나게 많은 전화번호 데이터를 추출해야 할 때
2. 사용자가 입력한 이메일, 휴대폰 번호, IP 주소 등이 올바른지 검증하고 싶을 때
3. 코드에서 특정 변수의 이름을 치환하고 싶지만, 해당 변수의 이름을 포함하고 있는 함수는 제외하고 싶을 때
4. 특정 조건과 위치에 따라서 문자열에 포함된 공백이나 특수문자를 제거하고 싶을 때
// 회원가입 할 때 전화번호 양식 검사
// ex) 010-1234-5678 의 경우 "숫자 3개", "-", "숫자 4개", "-", "숫자 4개" 형식
// \d 는 숫자를 의미, {} 안의 숫자는 개수를 의미
const regex = /\d{3}-\d{4}-\d{4}/;
regex.test('010-1234-5678'); // true
regex.test('010-12-34'); // falseRegExp.prototype.test()
test() 메서드는 주어진 문자열이 정규 표현식을 만족하는지 판별하고, 그 여부를 true 또는 false로 반환한다.
그러나 정규표현식은 주석이나 공백을 허용하지 않고 여러가지 기호를 혼합하여 사용하므로 가독성이 좋지 않다는 단점을 가지고 있다.
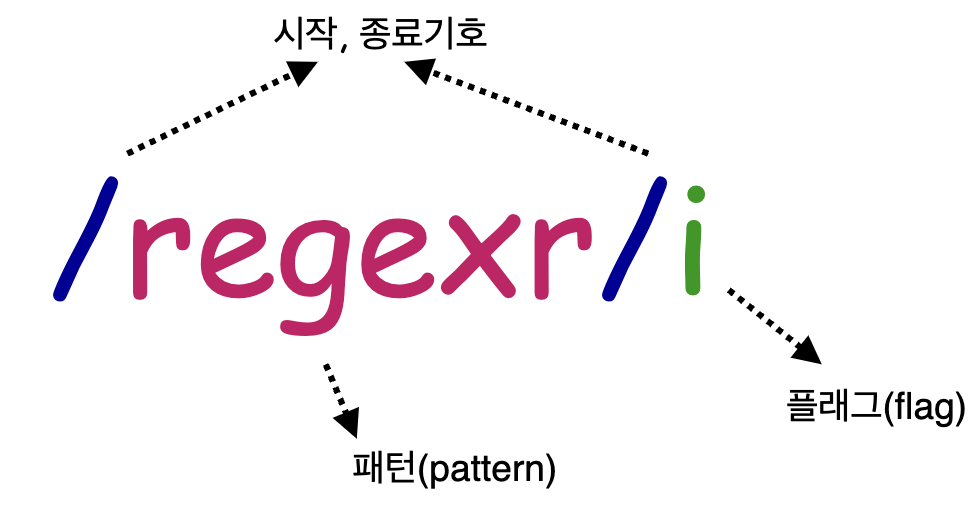
정규식 구성
정규식은 슬래쉬 문자 두 개 사이로 정규식 기호가 들어가는 형태이다.
뒤에 나오는 i 는 정규식 플래그이다.
// 리터럴 방식
const regex = /abc/;
// 생성자 방식
const regex = new RegExp(/abc/);
const regex = new RegExp("abc");정규식 메서드
| 메서드 | 의미 |
| (문자열).match(/정규표현식/) | 문자열에서 정규표현식에 매치되는 항목을 배열로 반환한다 |
| (문자열).replace(정규표현식, 대체문자열) | 정규표현식에 매칭되는 항목을 대체문자열로 변환한다 |
| (문자열).split(정규표현식) | 문자열을 정규표현식에 매칭되는 항목으로 쪼개어 배열로 반환한다 |
| (정규표현식).test(문자열) | 문자열이 정규표현식과 매칭되면 true를 반환하고, 아니면 false를 반환한다 |
| (정규표현식).exec(문자열) | match 메서드와 유사하나, 무조건 첫번째 매칭 결과만 반환한다. |
정규식 플래그
정규식 플래그는 정규식을 생성할 때 고급 검색을 위한 전역 옵션을 설정할 수 있도록 지원하는 기능이다.
// flag에 플래그 문자열이 들어감
const flag = "i";
const regex = new RegExp('abcated', flag);
// 리터럴로 슬래쉬 문자 뒤에 바로 표현 가능
const reg1 = /cat/i;
const reg2 = /cat/gm;
| 플래그 | 의미 | Description |
| g | Global | 문자열 내의 모든 패턴을 검색 |
| i | Ignore Case | 대소문자를 구별하지 않고 검색 |
| m | Multi Line | 문자열의 행이 바뀌더라도 계속 검색 |
| s | dotAll | .(모든 문자)이 개행 문자 \n 도 포함하도록 'dotAll' 모드 활성화 |
| u | unicode | 유니코드 전체를 지원 |
| y | sticky | 문자 내 특정 위치에서 검색을 진행하는 'sticky' 모드 활성화 |
1) g : 전역 검색
전역 검색 플래그가 없을 경우 최초 검색 결과 한번만 반환한다.
전역 검색 플래그가 있을 경우, 모든 검색 결과를 배열로 반환한다.
const ex1 = "abcdeabc";
// g 플래그 없이는 최초에 발견된 문자만 반환
ex1.match(/a/); // ['a', index: 0, input: 'abcdeabc', groups: undefined]
// g 플래그가 있으면 모든 결과 배열로 반환
ex1.match(/a/g); // ['a', 'a']
2) i : 대소문자 구분 없음
정규식은 기본적으로 대소문자를 구분한다.
i 플래그를 통해 대소문자를 구분하지 않을 수 있다.
const ex2 = "abcDeABC";
// 대소문자 a 검색
ex2.match(/a/gi); // ['a', 'A']
3) m: 줄바꿈 검색
여러 줄의 문자열에서 필터링 해야 할 경우 사용된다.
입력 시작(^) 앵커나 입력 종료($) 앵커는 전체 문자열이 아닌 각 줄 별로 대응되도록 만들어졌기 때문에
만약 여러 줄을 검색해야 한다면 m 플래그를 사용한다고 보면 된다. (앵커(`^`)는 문자열의 시작을 의미)
// 줄바꿈이 포함된 문자열
const ex3 = "Hello World and\nSJ Bye!\nSJ World";
/*
Hello World and
SJ Bye!
SJ World
*/
// Hello 단어로 시작하는지 검사
ex3.match(/^Hello/);
// ['Hello', index: 0, input: 'Hello World and\nSJ Bye!\nSJ World', groups: undefined]
// SJ 단어로 시작하는지 검사
ex3.match(/^SJ); // null
// 검색 X
// m 플래그 통해 개행되는 다음 줄도 검색되도록 설정
ex3.match(/^SJ/m);
// ['SJ', index: 16, input: 'Hello World and\nSJ Bye!\nSJ World', groups: undefined]
ex3.match(/^SJ/gm); // ['SJ', 'SJ']
4) s : .(all)에 개행문자(\n) 포함
s 플래그는 dot(.) 과 함께 쓰인다.
dot(.)은 모든 문자를 뜻한다.
// dot(.) 예시
const test = 'hello';
test.match(/./g); // ['h', 'e', 'l', 'l', 'o']
const ex4 = 'hello hello';
ex4.match(/hello.hello/);
// ['hello hello', index: 0, input: 'hello hello', groups: undefined]
// hello 사이에 개행문자 넣었을 경우
const ex4_ = 'hello\nhello';
ex4_.match(/hello.hello/); // null
// 패턴에 일치하지 않아 검색 x
ex4_.match(/hello.hello/s);
// ['hello\nhello', index: 0, input: 'hello\nhello', groups: undefined]
// 플래그 s 옵션을 주면 개행문자도 포함시켜 줌
5) u: 유니코드 패턴 사용
4바이트 문자를 2바이트 문자 2개로 처리하지 않고, 문자 1개로 올바르게 처리할 수 있다.
var ex5 = '🥺';
let reg = /./;
ex5.match(/./);
// ['\uD83E', index: 0, input: '🥺', groups: undefined]
console.log(ex55[0]); // �
ex5.match(/./u);
// ['🥺', index: 0, input: '🥺', groups: undefined]
// ----------------------
ex5 = ex5.replace(reg, '바나나');
console.log(ex5); // 바나나�
ex5 = ex5.replace(/./u, '바나나');
console.log(ex5); // 바나나일반적으로 정규식 패턴은 2바이트 기준으로 되어있다.
그런데 문자열 ex5 에 입력된 이모지는 4바이트 이다.
ex5.replace(reg, '바나나'); 의 코드를 보면,
이모지가 2바이트/2바이트로 분해되어 '바나나'로 치환되었지만 남은 2바이트는 위와 같이 이상한 문자로 표현된다.
이런 문제를 해결하기 위해 플래그 u 를 사용한다.
6) y : 문자 내 특정위치 검색
플래그 y는 lastIndex 속성과 함께 쓰인다.
// 예시 : 문자 내 특정 위치를 조회하고 싶은 경우
var ex6 = 'ab?de';
var reg = /./;
ex6 = ex6.replace(reg, '@');
console.log(ex6); //@b?de문자열 ex6의 3번째 문자에 무엇이 올 지 모르는 경우라고 가정해보자.
그리고 그 3번째 문자를 @ 로 치환하고 싶은 경우, y 플래그를 활용하면 해결할 수 있다.
var ex6 = 'ab?de';
var reg = /./y;
reg.lastIndex = 2;
ex6 = ex6.replace(reg, '@');
console.log(ex6); //ab@dey 플래그 옵션을 주고, 정규식 패턴에서 lastIndex 속성에 인덱스 값을 입력한다면 해당 인덱스 문자부터 패턴을 찾는다.
y 플래그의 단점
1. y 플래그는 g 플래그와 함께 쓰면 g 플래그와 lastIndex 속성이 모두 무시되어 올바른 결과를 낼 수 없다.
var ex6 = 'abdabc';
var reg = /a/gy;
reg.lastIndex = 3;
ex6 = ex6.replace(reg, '@');
console.log(ex6); // @bdabc결과를 보면, g 플래그도 lastIndex도 모두 무시되었다.
2. y 플래그는 해당 위치부터 패턴에 일치하는 것 1개만 찾고 동작을 멈춘다.
var ex6 = 'abcabcabc';
var reg = /a/y;
reg.lastIndex = 3;
ex6 = ex6.replace(reg, '@');
console.log(ex6); // abc@bcabc결과를 보면, g 플래그 옵션이 무시되므로 전역에서 검색할 수 없어서 특정 위치부터 패턴에 일치하는 것 1개만 찾을 수 있다.
3. lastIndex 속성은 일회성이다.
var ex6 = 'abcabcabc';
var reg = /a/y;
reg.lastIndex = 3;
var ex6_1 = ex6.replace(reg, '@');
console.log(ex6_1); // abc@bcabc
var ex6_2 = ex6.replace(reg, '@');
console.log(ex6_2); // abcabcabc
reg.lastIndex = 3;
var ex6_3 = ex6.replace(reg, '@');
console.log(ex6_3); // abc@bcabc결과를 보면, 똑같은 reg를 사용하여 치환했지만 ex6_2에선 a가 모두 치환되지 않았다.
일회성이기 때문에 한 번 사용 후 lastIndex 속성이 제거되었으므로 아무런 문자도 치환되지 않은 것이다.
그래서 ex6_3과 같이 치환하기 전 다시 lastIndex 속성을 주어야 한다는 불편함이 있다.
정규식 기호
정규표현식에서 사용되는 기호를 Meta 문자라고 표현한다.
표현식에서 내부적으로 특정 의미를 가지는 문자를 말한다.
정규식 특정 문자/숫자 매칭 패턴
| 패턴 | 의미 |
| . | 줄 바꿈 문자(\n)을 제외한 임의의 모든 문자(공백 포함) |
| \b | (word boundary) 63개 문자(영문 대소문자 52개 + 숫자 10개 + _(underscore))가 아닌 나머지 문자에 일치하는 경계(boundary) |
| \B | (non word boundary) 63개 문자에 일치하는 경계 |
| \d | (digit) 숫자 |
| \D | (non digit) 숫자가 아닌 것 |
| \s | (space) 공백 |
| \S | (non space) 공백이 아닌 것 |
| \w | (word) 밑줄 문자를 포함한 영숫자 문자 [A-Za-z0-9_] 와 동일 |
| \W | (non word) \w가 아닌 것 |
| \특수기호 | \* \^ \& \! \? 등등... |
정규식 검색 기준 패턴
| 기호 | 의미 |
| | | or |
| [xy] | 괄호 안의 문자들 중 하나. or 처리 묶음이라고 보면 된다. ex) /abc/ : "abc"를 포함 /[abc]/ : "a" or "b" or "c" /[가-다]/ : "가" or "나" or "다" |
| [x-z] | (range) x~z 사이의 문자를 의미 |
| [^문자] | (not) 괄호 안의 문자를 제외 |
| ^문자열 | 특정 문자열로 시작 |
| 문자열$ | 특정 문자열로 끝남 |
정규식 개수 반복 패턴
| 기호 | 의미 |
| .x | 임의의 한 문자의 자리수를 표현, 문자열이 x로 끝남을 의미 |
| x? | 존재여부, x 문자가 존재할 수도, 존재하지 않을 수도 있음 (없거나 최대 1개만) |
| x* | 반복여부, x 문자가 0번 or 그 이상 반복됨을 의미 |
| x+ | x 문자가 1번 이상 반복됨을 의미 (최소 1개 or 여러개) |
| *? | 없거나 있거나 and 없거나, 최대 1개 : 없음 {0} 과 동일 |
| +? | 최소 1개, 있거나 and 없거나, 최대 1개 : 1개 {1} 과 동일 |
| x{n} | x 문자가 n 번 반복됨을 의미 |
| x{n,} | x 문자가 n번 이상 반복됨을 의미 |
| x{n, m} | x 문자가 최소 n번 이상, 최대 m번 이하로 반복됨을 의미 |
정규식 그룹 패턴
| 기호 | 의미 |
| (x) | 그룹화 및 캡쳐, x를 그룹으로 처리함을 의미 - 일치한 내용 보존 |
| (?:y) | 그룹화(캡쳐X) - 일치하지만 내용은 보존 안함 |
| (x)(y) | 그룹들의 집합, 앞에서부터 순서대로 번호를 부여하여 관리, x와 y는 각 그룹의 데이터로 관리 |
| x(?=y) | 앞쪽 일치 (Lookahead), x 뒤 y일 때 x /ab(?=cd|ef)/ = "abcd" or "abef" 일 경우 둘다 "ab"를 취득 |
| x(?!y) | 부정 앞쪽 일치(Negative Lookahead), x 뒤 y가 아닐 때 x /\d+(?!\.)/ = 숫자 뒤에 . 이 없는 숫자를 취득 |
| (?<=y)x | 뒤쪽 일치(Lookbehind), y 뒤 x일 때 x /(?<=ab|cd)ef/ = "abef", "cdef" 인 경우 "ef" 취득 |
| (?<!y)x | 부정 뒤쪽 일치(Negative Lookbehind), y 뒤 x가 아닐 때 x /(?<!-)\d+/ = 음수(-)가 안붙는 숫자와 일치 |
| (?<x>y) | 캡쳐이름 - y를 찾아 그룹명 x에 저장 |
정규식 그룹화
'sususu'.match(/su+/); // ['su', index: 0, input: 'sususu', groups: undefined]
'suuusuuu'.match(/su+/); // ['suuu', index: 0, input: 'suuusuuu', groups: undefined]
위의 코드를 보면, 표현식 su+ 는 "u"만 +를 적용시킨다. ('s'는 적용시키지 않음)
그 결과로 suuu가 반환되었다.
'sususu'.match(/(su)+/); // ['sususu', 'su', index: 0, input: 'sususu', groups: undefined]
'suuusuuu'.match(/(su)+/); // ['su', 'su', index: 0, input: 'suuusuuu', groups: undefined]
표현식 (su)+ 는 "s"와 "o"를 그룹으로 묶었기 때문에 "su" 자체를 1회 이상 연속으로 반복되는 문자로 검색하게 된다.
따라서 결과로 'sususu'가 반환되었다.
(그런데 마지막으로 패턴 ()을 사용한 정규식들의 결과를 보면 플래그 g를 사용하지 않아도 일치한 결과가 2개가 나온다.)
정규식 캡처 기능
패턴 그룹화 () 는 괄호 안에 있는 표현식을 캡쳐하여 사용하는데, 여기서 캡쳐란 일종의 복사본을 생성하는 개념이라고 보면 된다. (복사라는 단어는 이해를 돕기 위해서 사용하는 것이지, 실제 개념과는 다르다.)
'sususu'.match(/(su)+/);
// ['sususu', 'su', index: 0, input: 'sususu', groups: undefined]정규식의 캡처 원리를 알아보자면, 패턴 ()안에 있는 "ko"를 그룹화하여 캡처(복사)한다.
우선 캡처된 표현식은 당장 사용되지 않으며, 그룹화된 "ko"를 패턴 +로 1회 이상 연속으로 반복되는 문자로 검색한다.
그렇게 캡처 외 표현식이 모두 작동하고 난 뒤에 복사했던(캡처된) 표현식 "ko"가 검색되는 것이다.
즉, 위의 검색 순서를 정리하면
1. 그룹화된 "su"를 패턴 +로 1회 이상 연속으로 반복하여 검색하여 "sususu"를 반환한다.
2. 캡처된 "su"로 검색하여 "su"를 추가로 반환한다.
'123abc'.match(/(\d+)(\w)/); // "123a", "123", "a"
/*
1. 패턴 () 안의 표현식을 순서대로 캡처한다 => \d+, \w
2. 캡처 후 남은 표현식으로 검색한다
3. 패턴 \d로 숫자를 검색하되, 패턴 +로 1개 이상 연속되는 숫자를 검색한다 => 123
4. 다음 패턴 \w로 문자를 검색하니 "a"가 일치한다
5. 최종적으로 "123a"가 반환된다
6. 첫 번째 캡처한 표현식 \d+로 숫자를 재검색하되, 패턴 +로 1개 이상 연속되는 숫자를 검색한다
7. "123"가 일치하여 반환된다
8. 나머지 캡처한 표현식 \w로 문자를 검색하니 "a"가 일치하여 반환된다
*/캡처하지 않는 그룹화
위에서 처럼 정규식 그룹화 캡쳐 기능으로 인해 쓸데 없는 결과값을 얻는 것이 싫다면, 괄호 안에 ?: 문자를 써서 캡쳐를 비활성화 할 수 있다.
// 그룹화 + 캡쳐
'sususu'.match(/(su)+/); // ['sususu', 'su', index: 0, input: 'sususu', groups: undefined]
// 그룹화만
'sususu'.match(/(?:su)+/); // ['sususu', index: 0, input: 'sususu', groups: undefined]
참조
https://opentutorials.org/course/909/5142
https://hamait.tistory.com/342
https://emunhi.com/view/202001/27234718474?menuNo=10000
'기타' 카테고리의 다른 글
| [Docker] Docker 컨테이너에 MySQL 설치하기 (1) | 2024.12.10 |
|---|---|
| 38회 ADsP 데이터분석 준전문가 합격 후기 (0) | 2023.11.22 |
| 5회 빅데이터분석기사 합격 후기 (1) | 2023.11.22 |


